이전에 RNN의 문제에 대해서 알아보았다..
- 병렬 처리 안 됨
- 선형 구조에 의존되어 문장을 이해하기 때문에 잘 처리하지 못함!
위와 같은 문제를 해결하기 위해 나온 solution이 Attention이다.
Core Idea
decoder의 각 step에서 encoder와의 직접 연결을 이용해서, source sequence의 특정 part에 집중한다.
전통적인 RNN은 인코더의 마지막 hidden state 하나만 보고 다음 단어를 예측했다! (정보 손실이 크다!! )
Basic Idea
attention이 없을 때 다음의 아이디어를 떠올렸다...
그러면... hidden state 정보 하나에 이전의 정보가 모두 잘 요약했다고 보장할 수 없으니까...? 그걸 다 요약하는 거 어때??
즉,
Encoder로부터 정보를 전달하는 가장 기본적인 방법은... encoder의 hidden state들을 평균(average) 내는 것이다!!
즉, decoder에 Encoder의 context vector를 전달하는 것!
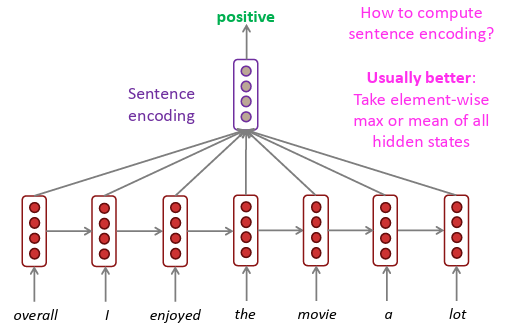
문장의 encoding을 계산할 떄 모든 hidden state들의 element-wise max 또는 mean을 취하는 것!
Attention
즉 weighted average를 통해서... weight가 높은 것을 비중으로 학습하는거지!!!

Attention에는 Query, Keys, Values로 구성되어 있다.
Query는 모든 Keys들과 부드럽게 매칭되어 0과 1 사이의 weight를 만든다.
그 weight를 Key에 해당하는 Value를 곱하고 모두 더한다.

Lookup table은 key들을 value에 Mapping한 table이다.
Query가 특정 Key와 일치하면, 그 Key에 해당하는 Value를 반환한다.
seq2seq with attention의 작동 방식

빨간색은 Encoder, 초록색은 Decoder 부분이라고 하자!
1. 각 input의 hidden state에 대해서 현재 st(decoder의 초기화 vector)를 곱해서 Attention scores를 계산한다.

2. SoftMax를 이용해서 계산한 scores를 probability distribution(이것이 진짜 가중치!)으로 바꿔준다.
Decoder timestep에서는 우리는 제일 먼저 encdoer hidden state 를 먼저 focusing 한다는 것을 알 수 있다.

3. 이 attention distribution(가중치)을 이용해서 encoder hidden state의 가중합을 계산한다.
계산된 attention output은 대부분 high attention을 가진 hidden state의 정보를 포함하게 된다.

6. attention output (context output)과 decoder hidden state를 연결해서 이를 기반으로 y1을 계산한다.

어떤 경우에는 이전 step의 attention output도 decoder input에 같이 넣는다.
In equations : 수식으로!
1. Encoder의 hidden states가 주어지고, timestep t에 대해서 decoder hidden state st가 있다고 하자.
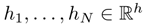

2. 이 step에 대해서 attention scores(단시 유사도 점수!) 를 계산하자!

즉 현재 st(Query)와 입력의 hidden state(
Values
)를 곱하면 된다.
3. 이 step의 attention distribution(attention Weight)을 계산한다. softmax 함수로! (확률 분포를 계산해주고, 합은 1)
즉, 각 st가 encoder hidden state에 대해서 얼마나 집중할지 확률처럼 해석 가능!!

4. 이 attention distribution(attention Weight)을 encoder hidden state(Values)와 weighted sum하여 attention output를 얻는다.

5. 이 attention output at와 decoder hidden state st를 이어 붙이고 decoder로 넘겨준다!!
정리..!
| Query qtq_t | 디코더의 현재 hidden state (t 시점) | “지금 어떤 정보가 필요하지?” |
| Keys kik_i | 인코더의 각 hidden state | 입력 단어들의 "정체성" |
| Values viv_i | 보통 Keys와 같고, 인코더의 hidden state 자체 | 입력 단어들의 실제 정보 |
| Attention distribution | Query와 각 Key 간의 유사도 → softmax로 만든 가중치들 | α1,α2,…,αT\alpha_1, \alpha_2, \dots, \alpha_T, 총합 = 1 |
| Attention output (context vector) | ∑iαi⋅vi\sum_i \alpha_i \cdot v_i | 집중한 값들의 가중 평균 |
Attention is awesome!
Attention은 parallelizable하고
bottlenck issues를 해결할 수 있다.
즉, 각 단어의 representation(==vector)을 Query로 사용해서 Values에서 정보를 가져오고 결합한다.
== 각 단어(Query)는 모든 단어를 탐색하여(key) 자기에게 필요한 정보만 골라낸다!
우리가 지금까지 본 것은 Cross-Attention(Decoder가 Encoder를 쳐다보는 것)
이제는 한 문장 안에서 단어들끼리 서로 주목하는 Self-Attention (단어들끼리 서로를 동시에 쳐다봄)을 보자!!
Self-attention은 특히 순차적으로 처리해야 하는 연산의 개수가 sequence 길이에 따라 늘어나지 않는다는 장점이 있다! 즉 GPU에 친화적이다!!
모든 word가 한 layer에서 서로 상호작용 하기 때문에 최대 interaction distance는 O(1)이다.

Attention is awesome Deep Learning technique
우리는... seq2seq 모델을 Machine Translation 하기 위해 개선한 방법인 attention을 보았습니다..
하지만!! 다른 많은 architextures, 그리고 많은 task에서 사용된다다!!
More general definition of attention :
• Given a set of vector values, and a vector query, attention a weighted sum of the values, dependent on the query.
어떤 경우에는 query 가 value에 attend한다. 라고 말한다.
지금까지 우리가 본 seq2seq + attention 구조에서는 Decoder의 각 hidden state (query)가 Encoder의 모든 hidden state (value)에 attention한다. (즉, 어떤 정보가 필요한지 attention을 통해 결정!)
정리: 직관
가중합 : query가 집중해야 할 값을 결정한 values들이 포함된 정보의 선택적 요약,
Attention은 아무리 많은 representation이 있어도 하나의 고정된 fixed-size representation(vector)을 뽑아낸다.
그 vector는 query가 어디에 집중했는지에 따라 달라진다.
Attention은 거의 모든 Deep Learning model에서 가장 강력하고 유연하고 일반적인 pointer이자 memory manipulation이다.
그래서 이 아이디어가 적용된게 NMT여!
추가 궁금증... 왜 Query(st)랑 Keys(input hidden state)를 dot product하는게 정보를 결합하는게 되는거야?
dot product는 결국 두 입력이 얼마나 관련 있는지 (유사도)를 측정하는 것! 그래서 Query(st)랑 Key(입력)얼마나 관련이 있는지 측정하고 value(=정보)를 얼마나 가져올지 결정하는게 정보 결합!!!!
근데 위의 모델에서는
Key = Value = Encoder Hidden State로 그냥 써버린 것!!
Transformer에서는 Key, Value는 hidden state에 다른 가중치 marix를 곱한다.
'AI & ML > LLM' 카테고리의 다른 글
| Pretraining (0) | 2025.07.06 |
|---|---|
| Transformer : Decoder (0) | 2025.06.22 |
| Transformer(1) : Self-attention (0) | 2025.06.21 |
| Machine Translation (MT)의 발전 (0) | 2025.06.21 |
| Language Modeling (0) | 2025.06.21 |