우리가 앞에서 Attention이 input sequence로부터 입력 ht에 중요한 information을 넘겨주는 것이라고 배웠다!
근데 RNN도 과거 시점의 information을 input로 전달하는 같은 목적이 다!
그렇다면... RNN을 굳이 쓸 필요가 있을까?? Attention이 정보를 넘겨주는 방식이라면!
그래서 Transformer가 등장!
Self-attention
Transformer를 이해하기 위해서는 self-attention을 이해해야 한다.
Cross Attention은
generate yt를 생성하기 위해 input x에 attention하 것! (지난 시간 배운 attention)
여기서
Self-Attention은
yt를 생성하기 위해 y<t에 attention하는 것!
즉, output seq를 생성하는데 현재 시점 t의 출력을 생성할 때 이전 출력들을 보고 생성한다!
이전 토큰들을 참고해서 중요도를 따지고 이용해서 생성한다!

Keys, Queries, Values
자 vocabulary V의 단어 sequence w1:n이 있다고 하자 (e.g Zuko made his uncle tea)
1. Embedding matrix E에 대하여 word embedding으로 바꾼다.
각 wi -> xi 로 바꿔준다. (Xi = Ewi)
2. weight Matrix Q, K, V를 각 word embedding으로 바꾼다.

3. Key와 Query의 similiaites를 계산하고 softmax로 normalize한다!
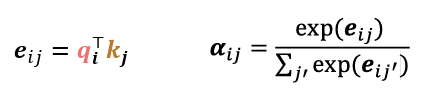
4. 그것을 가중합하여 계산!~~~

Self Attention의 장벽.. 그리고 Solutions!
1. 단어의 순서에 대한 정보가 아예 없잖아! : Sequence order

Sollutions: Position representations을 input에 추가해준다!
즉, key, query, value를 만들기 이전에 input embedding에 order information을 미리 넣어줘야 한다!
poisional encoding인 vector Pi 는 pi가 문장의 특정 위치(index)에 있음을 가리킨다. (실제로 sin,cos 로 구성된 고정된 vector 값임)

이를 input embedding에 그냥 더해주면 된다~~
그래서 xi~는 위치 정보를 반영한 최종 embedding이므로
positioned embedding, positional input이라고 부른다.
어떻게 Position representation을 만들까?
1. Sinusoidal position representations

sin, cos 함수로 변환해서 벡터로 표현!
장점
- vector 차원마다 주기와 dimension이 다르기 때문에 다양한 시점의 패턴을 표현 간으!
- 완전한 절대적 위치가 아닌 상대적 위치 차이(간격)이 더 중요하게 작동함!
- 입력 sequence가 길어져도 패턴이 반복될 수 있다! 그래서 안 본 길이까지 일반화(extrapolation)할 수 있음!
단점
- Not learnable: 완전히 고정된 함수로 만들어져서, 학습 중에 모델이 자유롭게 조정하거나 최적화 X
- extrapolation 사실 안됨 : 긴 입력에 대해서 성능이 똑같이 잘 안 나옴...
2. scratch(처음부터, 제로로)로 부터 Position representation vectors를 학습시키자!
Absolute poistion representation을 배우자!
pi를 학습가능한 parameter도 두자~~ pi는 P matrix의 matrix column으로 두자!
장점
- 유연하다.
단점
- 일반화 X : 만약 훈련 시 최대 n의 길이인 문장 보았는데... 그 이상의 문장이 들어오면?? 안 됨
3. RoPE : Common, modern position embeddings
- 다시 생각해보자.
positioned embedding을 f(x, i) 형태로 relative position embedding으로서 생각해보자.
f(x, i) : 단어 x의 위치 i에서의 embedding이라고 해보자 (x는 단어, i는 위치)

여기서 Attention function g는 x, y의 의미와 (i-j)라는 상대적 위치 차이에만 의존해야 한다!!
기존의 positional embedding은 이 목표를 충족시키지 못 하는가?
- 1의 경우 : 상대적이지 않은 다양한 cross-term을 가진다. (절대 위치 정보가 따로따로 반영된 것)
- 2의 경우 : (i-j)에 대하여 inner product로 표현되지 않는다.
- Embedding via rotation
우리는 position embedding이 absolute position에 영향을 받지 않게 하고 싶음! -> relative position으로!
우리는 inner products가 arbitrary rotation에 변하지 않는다는 것을 알고 있어! -> 내적 값은 동일해!

내적 기반으로 attention score를 계산하면..! 상대 위치 기반 attention이 가능하다!

따라서 coordinate를 짝지어서 2D 평면에서 회전시켜라!!! (아이디어는 복소수에서 따온 것!!)
즉 위치 i에 대하여 단어 vector x에 대해서 sin/cos을 곱하여 벡터 공간에서 회전시키자!
위의 그림을 보면
각 단어는 d 차원의 Query/Key 벡터를 가진다! 그리고 poision이 적용 된 후 Position embdding(위치 정보가 내제된) Query/Key가 생성된다.
단어 Enhanced에 대한 Query와 Key vector (x1, x2)가 존재하고 position m(index임)이 있다.
이때 Q, K vector(x1, x2)를 sin/cos 기반으로 m만큼 회전시킨다. 그러면 반영이 되고!!
그러면!! 회전이 반영된 vector된 후 Enhanced라는 Q 벡터(위치 1)와 Rotary라는 단어의 K 벡터(위치 4)가 dot product하여 attention score 계산 시 위치 정보가 반영이 된다~~~
2. Deep Larning을 위한 nonlinearities가 없워!! 그냥 단순히 weighted 평균이자냐 : non-linearities

Self-attention 메커니즘 자체에는 비선형성 이 없다... 전부 선형 연산임!!
따라서 Self-attention만 계속 쌓다보면
- 이전 layer에서 얻은 Value vector들을 다른 방식으로 재평균(re-averaging) 하는 것에 불과하게 됨
Solutions: Self-attention 이후 Feed-Forward network로 비선형성을 추가하여 각 output vector를 처리함!

3. sequence를 예측할 때 "미래를 보지 않는다"는 보장이 있나? : Masking the future in self-attnetion
이 말은 즉슨, Machine translation이나 Language modeling과 같이 순차적인 task에서 아직 나오지 않은 단어를 미리 참고하면 안 된다는 뜻!!! (self-attention은 input 전체를 확인하니까!) -> 즉, training 할 때! (inference는 아님!!)

Decoder는 기본적으로 self-attention과 cross-attention을 사용한는데,
train 도중에 input과 target을 모두 받는다. 이때 단어 예측하는데 self-attention 시 target seq 전체를 참고할 수 있으니, 이를 가려야 함.
그러면 매 timestep마다 keys들과 querys를 바꿔서 이전 단어만 보게 만들면 될까? -> Inefficient!
매 timestep마다 attention 범위를 다시 설정해야 하므로 병렬 계산이 불가능...
즉, paralleization이 가능하려면
- 전체 seq를 다 넣은 후
- future 단어들의 attention scores를 -무한대로 설정하여 attention을 mask out 처리해야 함!
- softmax에서 exp (−∞ ) = 0이므로 완전히 무시된다~~


Solutions: attention weight를 0으로 일부러 만들어서 미래를 mask out한다.
정리 : Self-attention을 위한 building block!

1. self-attention
2. Position representations
seq oreder를 구체화하기 위해서! self-attention은 input의 순서를 고려하지 않기 때문에!
3. nonlineariies
self-attention block의 output에 Feed Forwar newrok를 구현!
4. Masking
미래를 보지 않고 parallize 연산을 하기 위해서
- 미래에 생성돼야 할 단어의 정보가
- 앞 단어 예측 과정에 흘러 들어가면 안 됨 ❌
- Masking은 이런 **정보 누출(leakage)**을 막아줌
'AI & ML > LLM' 카테고리의 다른 글
| Pretraining (0) | 2025.07.06 |
|---|---|
| Transformer : Decoder (0) | 2025.06.22 |
| Attention (0) | 2025.06.21 |
| Machine Translation (MT)의 발전 (0) | 2025.06.21 |
| Language Modeling (0) | 2025.06.21 |